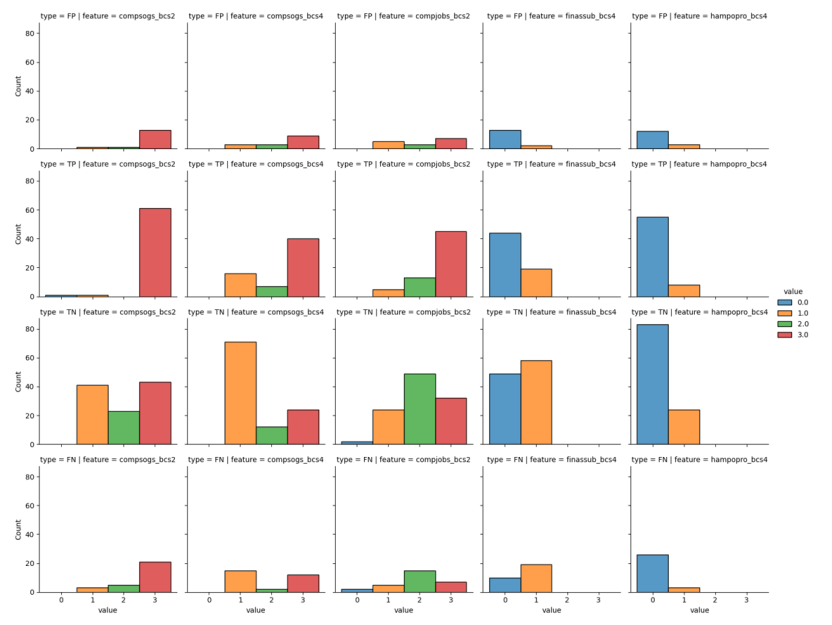
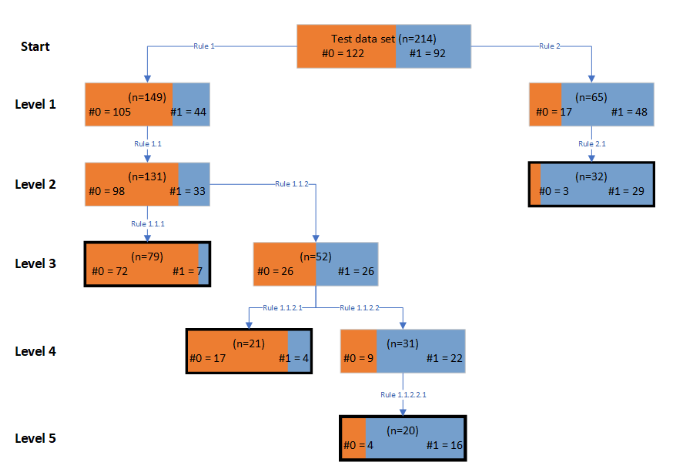
Level 1:
Rule 1: compsogs (2019-20) < 3 OR compsogs (2017-18) = 1 OR hampopro (2019-20) = 1.
The complement of the set defined by Rule 1 is found by Rule 2:
Rule 2: compsogs (2019-20) = 3 AND compsogs (2017-18) ≠ 1 AND hampopro (2019-20) = 0.
Level 2:
Rule 1.1: compprod (2019-20) < 3 OR compjobs (2017-18) = 1
Rule 2.1: compprod_bcs summed over 2017-18 to 2019-20 ≥ 7.
Path to leaf: Using the sequence of restrictions formed by Rule 2 AND Rule 2.1, we can define an overall rule H1 aimed at recognising higher-score businesses:
Step 1. compsogs (2019-20) = 3 AND compsogs (2017-18) ≠ 1 AND hampopro (2019-20) = 0,
Step 2. compprod_bcs summed over 2017-18 to 2019-20 ≥ 7.
Discussion: Step 1 retains those businesses which did not decrease their sales of goods and services in 2017-18, increased these sales in 2019-20, and did not have to lower their profit margins to remain competitive in 2019-20.
Of these businesses, Step 2 retains those which reported a decrease in productivity at most once in the period 2017-18 to 2019-20.
Leaf result: Applying the overall rule H1 to the test set leads us to correctly recognise 29/92 (≈31.5%) high-profit score businesses. The associated misclassification of low-score businesses is 3/122 (≈2.5%). This is quite a discriminating rule.
Level 3:
Rule 1.1.1: 0 < compprod_bcs (2019-20) < 3.
Path to leaf: Using the sequence of restrictions formed by Rules 1, 1.1, and 1.1.1, we can define an overall rule (L1) aimed at recognising lower-score businesses:
Step 1. compsogs (2019-20) < 3 OR compsogs (2017-18) = 1 OR hampopro (2019-20) = 1,
Step 2. compprod (2019-20) < 3 OR compjobs (2017-18) = 1,
Step 3. 0 < compprod_bcs (2019-20) < 3.
Discussion: Step 1 of L1 excludes businesses that have increasing income from sales of goods and services for 2017-18 and 2019-20 which also reduced their profit margins in 2019-20. The condition does allow for variability in income from sales over time.
Similarly, Step 2 further excludes businesses that both increased profitability in 2019-20 and had the total number of jobs and positions in 2017-18 stay steady or increase.
Step 3 omits businesses that increased productivity in 2019-20 (as well as the indeterminate case of a “not applicable” response).
Leaf result: This overall rule leads us to correctly recognise 72/122 (≈59%) of lower-score businesses. The associated misclassification of higher-score businesses is 7/92 (≈7.6%). This rule has some ability to discriminate between groups of businesses.
Rule 1.1.2 finds the complement of the set defined by Rule 1.1.1.
Rule 1.1.2: compprod_bcs (2019-20) equals 0 or 3.
Level 4:
Rule 1.1.2.1: sum compprod from 2017-18 to 2019-20 ≤ 6.
Path to leaf: Using the sequence of restrictions formed by Rules 1, 1.1, 1.1.2, and 1.1.2.1 we define a second overall rule (L2, which shares its first two steps with L1) aimed at recognising one type of low-score businesses:
Step 1. compsogs (2019-20) < 3 OR compsogs (2017-18) = 1 OR hampopro (2019-20) = 1,
Step 2. compprod (2019-20) < 3 OR compjobs (2017-18) = 1,
Step 3. compprod (2019-20) equals 0 or 3,
Step 4. sum compprod from 2017-18 to 2019-20 ≤ 6.
Leaf result: This overall rule leads us to correctly recognise 17/122 (≈14%) lower-score businesses. The associated misclassification of higher-score businesses is 4/92 (≈ 4.3%). This rule has some ability to discriminate between businesses.
Rule 1.1.2.2 finds the complement of the set defined by Rule 1.1.2.1.
Rule 1.1.2.2: sum compprod_bcs from 2017-18 to 2019-20 > 6.
Level 5:
Rule 1.1.2.2.1:
For 2019-20: finassub_bcs + hampopro_bcs + skuscbus_bcs + compcont_bcs ≥ 2, OR
compjobs_bcs (2017-18) ≥ 2 AND compsogs_bcs (2019-20) ≥ 2.
Path to leaf: Using the sequence of restrictions formed by Rules 1, 1.1, 1.1.2, 1.1.2.2, and 1.1.2.2.1, we can define a second overall rule (H2) aimed at recognising higher-score businesses gives:
Step 1. compsogs (2019-20) < 3 OR compsogs (2017-18) = 1 OR hampopro (2019-20) = 1,
Step 2. compprod (2019-20) < 3 OR compjobs (2017-18) = 1,
Step 3. compprod (2019-20) equals 0 or 3,
Step 4. sum compprod from 2017-18 to 2019-20 > 6,
Step 5. For 2019-20: finassub + hampopro + skuscbus + compcont ≥ 2, OR
compjobs (2017-18) ≥ 2 AND compsogs (2019-20) ≥ 2.
Discussion: Notably, Steps 1 and 2 of H2 (subsetting the test set down to level 2 of Figure 9) favour a higher proportion of lower-profit businesses. However, many are excluded by later steps to produce a clear majority of higher-profit businesses later on the path. Step 3 is useful as it retains the compprod (2019-20) = 0 businesses that cannot be categorised with rules seeking high values of features or sums of values. Step 4 works to largely separate the lower and higher-profit businesses at level 4 of the decision tree into different nodes. Step 5 shows that, as we have already made most simple and decisive splits at higher levels of the tree, further splits may need to become more complicated. The first condition of Step 5 considers some lower-importance features, trialling a condition where a business may have two or more positive responses to a No/Yes question for four individual features, without specifying which. The second condition of Step 5 is included as an attempt to discriminate against the low values seen for certain features in low-score businesses.
Leaf result: Using the overall rule H2, 16/92 (≈17.4%) higher-score businesses are classified correctly. The associated misclassification of lower-score businesses is 4/122 (≈3.3%). This rule has some ability to discriminate between businesses.
Combining rules L1 and L2: 89/122 (≈73%) lower-score businesses are recognised correctly, with 11/92 (≈12%) misclassified higher-score businesses.
Combining rules H1 and H2: 45/92 (≈48.9%) higher-score businesses are recognised correctly with 7/122 (≈5.7%) misclassified lower-score businesses.
Together, the four rules correctly recognise 134/214 (≈62.6%) businesses with 18/214 (≈8.4%) businesses incorrectly categorised. Considering only those 154 businesses screened by these rules (≈72% of the total in the test set), 134/152 (≈88.2%) were correctly recognised.