|
|
TECHNICAL NOTE 3 FINER LEVEL MANUFACTURING INDUSTRY ESTIMATES
INTRODUCTION
The Manufacturing Industry data cube contains finer level estimates for the Australian manufacturing industry for the 2010-11 reference period.
Historically, the Australian Bureau of Statistics (ABS) collected manufacturing data at the class level of the Australian and New Zealand Standard Industrial Classification 2006 (ANZSIC), using survey methodology based on the direct collection of data. The latest estimates produced by this methodology are published in Manufacturing Industry, Australia, 2006-07 (cat. no. 8221.0).
This issue presents the fourth release of manufacturing estimates using a modelled methodology, which since the 2006-07 reference period, were released in Experimental Estimates for the Manufacturing Industry, Australia (cat. no. 8159.0). These estimates should be of substantial benefit to analysts and decision makers (including businesses themselves) who require finer levels of detail regarding industry classification.
The estimates use a combination of data directly collected in ABS surveys and Business Activity Statement (BAS) data sourced from the Australian Taxation Office (ATO). Modelling techniques are applied to combine these two data sources in order to produce estimates at the national ANZSIC class and state/territory ANZSIC subdivision levels. The methodology used to compile these statistics is described below in Concepts and Methods.
The estimates presented in the Manufacturing Industry data cube are produced for a select number of data items where ABS data and BAS data are well correlated. In the 2006-07 and 2007-08 issue of Experimental Estimates for the Manufacturing Industry, Australia (cat. no. 8159.0), these data items included wages and salaries, sales and service income and industry value added (IVA). The 2008-09 issue included experimental estimates for employment together with the data items previously published. In addition, a state and territory breakdown by ANZSIC subdivision was provided for the first time for wages and salaries, sales and service income and employment. This 2010-11 release continues with those data items published in 2008-09 and 2009-10.
The methodology used to compile these estimates is subject to continued evaluation and possible further change.
FUTURE PLANS
In the absence of directly collected data the ABS intends to release modelled, national ANZSIC class and state/territory ANZSIC subdivision level estimates for the manufacturing industry on an annual basis and released in Australian Industry, 2010-11 (cat no. 8155.0). The ABS is currently evaluating this methodology to see if it can be extended to satisfy other areas of unmet demand. The following areas are being considered, subject to rigorous evaluation:
- national ANZSIC class and state/territory ANZSIC subdivision level estimates for other industries
- additional data items such as profit measures.
ABS DATA AVAILABLE ON REQUEST
There are no further estimates, based on this alternative methodology, available for the manufacturing industry for the 2006-07 to 2010-11 reference periods or earlier years.
RELATED PUBLICATIONS
Other ABS publications and products which may be of interest are listed below. These publications are available free of charge from the ABS web site.
CONCEPTS AND METHODS
SCOPE AND POPULATION
The manufacturing estimates in this data cube are classified by industry, in accordance with the 2006 edition of the Australian and New Zealand Standard Industrial Classification (ANZSIC), 2006 (cat. no. 1292.0) and by institutional sector, in accordance with the 2008 edition of the Standard Institutional Sector Classification of Australia (SISCA), which is detailed in Standard Economic Sector Classifications of Australia (SESCA), 2008 (cat.no. 1218.0).
The scope of the manufacturing estimates is based on the scope used for the Economic Activity Survey (EAS) estimates which are presented in Australian Industry, 2010-11 (cat no. 8155.0). It includes all business entities in the Australian economy which are classified, on the ABS Business Register (ABSBR), to ANZSIC Division C Manufacturing but excludes any entities classified to SISCA Sector 3 General government. Note that government-owned or controlled Public non-financial corporations are included. |
 |
METHODOLOGY
The manufacturing estimates in this release were produced using a combination of data collected directly by the ABS and BAS data obtained from the ATO. The methodology used was essentially the same as in previous releases of Experimental Estimates for the Manufacturing Industry, Australia, 2006-07, 2007-08, 2008-09 and 2009-10 (cat. no. 8159.0).
The Manufacturing Estimates Model
The estimation method used to create the manufacturing estimates makes use of observed linear relationships between data collected from businesses in the EAS and auxiliary information available from BAS data. Where the auxiliary information is strongly correlated with data items collected in the EAS, this information has been used to create predicted values for non-profiled businesses and small profiled businesses that were not selected in the survey. The auxiliary variables used to create predicted values were:
- BAS total sales (to model sales and service income)
- BAS wages and salaries (to model wages and salaries, industry value added and employment).
Modelling was used on the BAS data rather than substituting it directly as the BAS data items did not map directly to their corresponding EAS data item definitions.
The ANZSIC class manufacturing estimates for 2010-11 were created subject to the constraint of being additive to national ANZSIC subdivision estimates produced from the EAS. This is also true for state/territory estimates: the state/territory estimates within an ANZSIC subdivision were constrained to sum to the EAS estimate. This means that the aggregate across all state/territory estimates for a given subdivision aligns with the EAS national subdivision estimate. However, the aggregate across all ANZSIC subdivision estimates for a given state/territory were not constrained to add to the state/territory by ANZSIC division level EAS estimates. Consequently, for each state and territory, there are minor differences between the division level estimates contained in this data cube and EAS estimates presented in Australian Industry, 2010-11 (cat no. 8155.0).
For the purpose of compiling ANZSIC class estimates, for Division C Manufacturing in this data cube, data for businesses are sourced via one of three categories (or 'streams') in accordance with significance and collection-related characteristics. The diagram below illustrates the ways in which the data streams contribute to the finer level estimates for the manufacturing industry.
SUMMARY OF DATA STREAMS
CONTRIBUTION OF DATA STREAMS TO FINER LEVEL ESTIMATES

The Survey Stream
The survey stream consists of businesses with directly collected EAS data. These are the completely enumerated businesses (those with employment of at least 300); and randomly sampled businesses, with employment less than 300 and exceeding a minimum turnover threshold level from the ABS Business Register. Directly collected EAS data were used for these units.
The Micro Non-Employing Stream
This stream includes units from the survey population which are non-employing businesses operating in only a single state or territory and whose turnover is below the turnover threshold for its ANZSIC class. For these businesses BAS data is directly substituted for sales and service income and wages and salaries. Simple modelling of BAS data is used to create industry value added. Employment is based on the business type of (legal) structure, e.g. a sole proprietor or partnership.
The Modelled Stream
The modelled stream includes all businesses not selected in EAS (the survey stream), or not in the micro non-employing stream as defined above (in EAS collection design).
Modelled data were created through the use of robust, trimmed regression estimators, which used survey data regressed against BAS data. The BAS data were found to have a high correlation with corresponding data from the EAS.
The regression factors were obtained by utilising units from the survey stream and comparing their reported survey data with their matching BAS data. These regression factors were created at the ANZSIC subdivision level. Sales and service income was modelled using BAS total sales as the auxiliary variable; wages and salaries, employment and IVA were modelled using BAS wages and salaries. Modelling of employment also took into account the business type (i.e. type of legal organisation) using a factor created at the ANZSIC division level.
Modelled data for units in the modelled stream were created by multiplying their BAS data by the calculated regression factors.
PRODUCING THE MANUFACTURING ESTIMATES
Initial national ANZSIC class and state/territory ANZSIC subdivision estimates for the manufacturing industry were produced by aggregating the contributing data streams. Additional rules were applied to produce state/territory ANZSIC subdivision estimates:
- for businesses (from any stream) operating in only a single state or territory, their initial estimates contributed to the relevant state or territory and ANZSIC subdivision estimates
- for businesses, from the survey stream, operating in more than one state or territory, their initial estimates (i.e. directly collected EAS data) contributed to the states and territories in alignment with the EAS methodology.
- for businesses, from the modelled stream, operating in more than one state or territory, their initial estimates were prorated across the states and territories in which they operated, based on a factor calculated at the ANZSIC division level from surveyed multi-state units of similar size. These modelled multi-state businesses accounted for only a small proportion of the estimates.
As explained earlier under Methodology initial estimates at the national ANZSIC subdivision level were then adjusted to equal national estimates produced from the EAS. This adjustment removed some of the non-sampling error introduced through the regression modelling. This adjustment was obtained by first calculating the difference between the EAS national ANZSIC subdivision estimates and the initial ANZSIC subdivision estimates. This difference was then prorated across the ANZSIC classes and states/territories within the ANZSIC subdivision. Proration only applied to the modelled stream, thus the level of proration for each class or state/territory was determined by the size of the modelled stream. As a result, proration had a stronger impact on those classes and states/territories with a larger modelled stream.
ASSUMPTIONS IN THE MODEL
The modelling methodology used to create the estimates presented in this data cube is based on the following assumptions:
- the national ANZSIC subdivision estimates and state/territory division estimates produced from the EAS were of sufficient quality to warrant disaggregation, respectively, at ANZSIC class level and state/territory level
- it was valid to distribute the difference between EAS national subdivision estimates and the initial subdivision estimates, based on the size of the modelled stream
- the relationship between the EAS data items and the BAS data items is meaningful and consistent. Analysis supports this assumption, with the correlation being of consistent quality to produce reliable estimates
- the auxiliary (BAS) data was of high quality
- the industry coding was accurate on both the ATO maintained ABR and the ABS maintained Business Registers.
|
|
RELIABILITY OF THE ESTIMATES
DATA QUALITY
When interpreting the estimates it is important to take into account factors that may affect the reliability of the estimates.
The quality of the estimates is limited by two issues:
- the validity of the assumptions underpinning the modelling
- the accuracy of the data used in the production of the estimates.
The assumptions used in the production of the estimates were outlined in Concepts and Methods. Users should consider the suitability of these assumptions when interpreting the estimates.
Examination of the following quality indicators will also assist users in determining fitness for purpose of the estimates of the manufacturing industry.
DATA USED IN THE CALCULATION OF THE ESTIMATES
The estimates presented in this data cube were obtained using a combination of data directly collected in the EAS and BAS data. Modelling techniques were applied to combine these two data sources in order to produce the estimates, as described earlier under Concepts and Methods.
The EAS uses a sample of businesses, rather than full enumeration (i.e. a census) and is subject to sampling error. The resultant estimates obtained from the regression model may be different if survey information were available for all businesses. The estimates presented in the data cube therefore have an associated sampling error.
The estimates also have additional associated sampling error as a result of constraining them to aggregate to national ANZSIC subdivision estimates obtained from the EAS.
SAMPLING ERROR
One measure of sampling variability is given by the standard error which indicates the extent to which an estimate might have varied by chance because only a sample of businesses was included. There are about two chances in three that a sample estimate will differ by less than one standard error from the figure that would have been obtained if a census were conducted, and about 19 chances in 20 that the difference will be less than two standard errors.
Sampling variability can also be measured by the relative standard error (RSE) which is obtained by expressing the standard error as a percentage of the estimate to which it refers. The RSE is a useful measure in that it provides an indication of the sampling error in percentage terms, and this avoids the need to refer also to the size of the estimate.
Approximate RSEs for the manufacturing industry estimates have been created using a replicate method. This method uses replicate final estimates created using sub-samples of reported data to estimate the variance of the estimate.
Distribution of RSEs
An indication of the size of RSEs is set out below for both the national ANZSIC class and state/territory ANZSIC subdivision estimates.
National ANZSIC Class Estimates
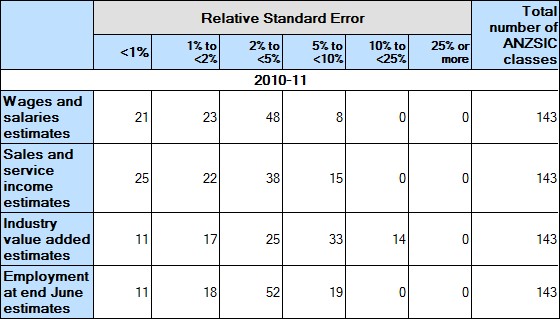
Below is a table which shows the distribution of RSEs for national ANZSIC class estimates for the manufacturing industry for 2010-11. All national ANZSIC class RSEs were less than 25%.
State/Territory ANZSIC Subdivision Estimates
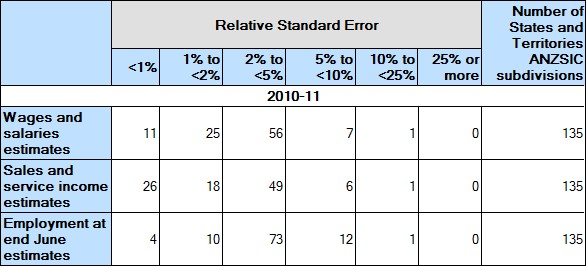
The table below shows the distribution of RSEs for state/territory ANZSIC subdivision estimates for the manufacturing industry for 2010-11. No state/territory ANZSIC subdivisions had RSEs of 25% or greater.
NON-SAMPLING ERROR
There are a range of other potential errors that are not caused by sampling and can occur in any statistical collection, whether it is based on full enumeration, a sample, or modelling. Non-sampling error may be due to inadequacies in available sources from which the population frame was compiled, imperfections in reporting by providers, errors made in collections such as recording and coding data, and errors made in processing data.
Although it is not possible to quantify non-sampling error, every effort is made to reduce it to a minimum. Collection forms are designed to be easy to complete and assist businesses to report accurately. Efficient and effective operating procedures and systems are used to compile the statistics. The ABS compares data from different ABS (and non-ABS) sources relating to the one industry, to ensure consistency and coherence.
If non-sampling error is systematic (i.e. not random) then the estimates will be distorted in one direction and therefore will be unrepresentative of the target population. Systematic error results in bias.
MODEL BIAS
As noted in Experimental Estimates for the Manufacturing Industry, Australia, 2009-10 (cat. no. 8159.0), use of a regression model may introduce bias. While it is not possible to calculate the size of the modelling bias, a comparison of 2006-07 experimental ANZSIC class estimates with the official ANZSIC class estimates published in Manufacturing Industry, Australia, 2006-07 (cat. no. 8221.0) did not indicate obvious systematic error or bias.
VALIDITY OF THE METHODOLOGY
Previous issues of this publication noted that, for the 2006-07 EAS, the sample size was increased to enable ANZSIC class data to be published in Manufacturing Industry, Australia, 2006-07 (cat. no. 8221.0). In order to test the validity of the estimates methodology, ANZSIC class level experimental estimates for 2006-07 were produced from what would have been the usual EAS sample size. These estimates compared favourably with the official estimates published in Manufacturing Industry, Australia, 2006-07, lending support to the validity of the experimental estimates methodology. |
|
|
|
 Quality Declaration
Quality Declaration  Print Page
Print Page
 Print All
Print All