|
USING THE CURF
ABOUT THE CURF
COUNTS AND WEIGHTS
IDENTIFIERS
MULTI-RESPONSE ITEMS
CURF DATA FILES
INFORMATION FILES
ABOUT THE CURF
The 2015 SDAC Basic CURF contains unit records relating to individual respondents to the Survey of Disability, Ageing and Carers. The data are released under the Census and Statistics Act 1905, which has provision for the release of data in the form of unit records where the information is not likely to enable the identification of a particular person or organisation. Accordingly, there are no names or addresses on the CURF and other steps, including the following list of actions, have been taken to protect the confidentiality of respondents:
- households with seven or more persons were reduced to a maximum size of six persons. This was done across a variety of ages and in ways that minimised the impact on family and relationship coding. This reduction also resulted in the deletion of several whole income units, mainly single person records
- some data items that were collected have been excluded
- the level of detail of certain data items has been reduced by grouping, ranging or top coding values
- several demographic characteristics for a number of person records have been changed.
The nature of the changes made, and the relatively small number of records involved ensure that the effect on data for analysis purposes is considered negligible. These changes also mean that estimates produced from the Basic CURF may differ from those published in Disability, Ageing and Carers, Australia: Summary of Findings, 2015 (cat. no. 4430.0), subsequent publications and any TableBuilder or DataLab output. Information about the impact of confidentialising actions on the CURF and comparison to published estimates for key populations can be found in Tables 1 and 2 below.
Table 1 compares previously published data with CURF data to show the size of the change to the estimated population. It can be seen that, proportionally, the largest impact of the confidentialising process is in relation to Northern Territory estimates.
Table 1: Published (cat.no. 4430.0) population estimates (weighted) compared to the CURF estimates
|  |
 | Published | CURF |  |  |
 | '000 | '000 | % change |  |
|  |
| New South Wales | 7,569.40 | 7,514.23 | -0.73% | |
| Victoria | 5,925.60 | 5,897.18 | -0.48% | |
| Queensland | 4,683.85 | 4,662.87 | -0.45% | |
| South Australia | 1,673.81 | 1,668.25 | -0.33% | |
| Western Australia | 2,490.47 | 2,479.29 | -0.45% | |
| Tasmania | 510.11 | 507.66 | -0.48% | |
| Northern Territory | 177.20 | 175.20 | -1.13% | |
| Australian Capital Territory | 383.23 | 381.11 | -0.55% | |
| Total | 23,413.67 | 23,285.78 | -0.55% | |
| | | | |
|  |
Table 2 shows that the impact of the confidentialising actions on high level target population estimates is small.
Table 2: Published (cat.no. 4430.0) disability and carer prevalence, and percentage of population aged 65 years or more, compared to the CURF
|  |
| Disability rate | | Carer rate | | Persons aged 65 years or more | |
 | | | | |  |
| |
 | Published | CURF | | Published | CURF | | Published | CURF |  |
 New South Wales New South Wales | 18.1 | 18.14 | | 11.9 | 11.94 | | 15.7 | 15.82 |  |
| Victoria | 18.5 | 18.54 | | 12.4 | 12.43 | | 15.1 | 15.13 |  |
| Queensland | 18.3 | 18.34 | | 10.1 | 10.14 | | 14.5 | 14.59 |  |
| South Australia | 22.9 | 22.87 | | 14.5 | 14.47 | | 17.6 | 17.6 |  |
| Western Australia | 14.6 | 14.56 | | 8.1 | 8.13 | | 13.5 | 13.56 |  |
| Tasmania | 25.8 | 25.86 | | 16.5 | 16.47 | | 18.4 | 18.44 |  |
| Northern Territory | 11.7 | 11.66 | | 6.6 | 6.56 | | 7.9 | 8.03 |  |
| Australian Capital Territory | 16.2 | 16.17 | | 11.7 | 11.71 | | 12.4 | 12.47 |  |
| Total | 18.3 | 18.33 | | 11.5 | 11.53 | | 15.1 | 15.23 |  |
| | | | | | | | |  |
|  |
Steps to confidentialise the datasets made available on the CURF are undertaken in such a way as to ensure the integrity of the datasets and optimise the content, while maintaining the confidentiality of respondents. Intending purchasers should ensure that the data they require at the level of detail they need are available on the CURF; data obtained in the survey, but not contained on the CURF may be available in TableBuilder, the DataLab or in tabulated form on request. The Data Item Lists document on the Summary tab contains information about the list of data items, which is available as an Excel spreadsheet on the Downloads tab.
COUNTS AND WEIGHTS
The 2015 SDAC collected data from 63,033 people living in 25,458 private dwellings, 482 people living in 348 self care retirement village units and 11,696 living in 1,009 cared accommodation establishments. After removing people to ensure confidentiality a total of 74,862 remain on the CURF. The number of records contributing to each of the different levels is shown in Table 3.
Table 3: Number of records by level for the SDAC 2015 CURF
|  |
 | | |  |
 Level Level | Counting unit | Number of records |  |
|  |
 Household level Household level |  Household Household | 25,801 | |
 Family level Family level |  Family Family | 27,319 | |
| Income Unit level |  Income Unit Income Unit | 31,903 | |
 Person level Person level |  Person Person | 74,862 | |
 All conditions level All conditions level |  Conditions Conditions | 139,129 | |
 Restrictions level Restrictions level |  Restrictions Restrictions | 119,011 | |
 Specific activities level Specific activities level |  Specific activities Specific activities | 169,913 | |
 All recipients level All recipients level |  Recipients Recipients | 5,812 | |
 Broad activities level Broad activities level |  Broad Activities Broad Activities | 91,008 | |
 Assistance providers level Assistance providers level |  Assistance providers Assistance providers | 30,737 | |
|  |
Weights and Hierarchical Files
As the survey was conducted on a sample of private households and a sample of health establishments in Australia, it is important to take account of the method of sample selection when deriving estimates from the CURF. This is particularly important as a person's chance of selection in the survey varied depending on the state or territory in which the person lived. If these chances of selection are not accounted for by use of appropriate weights, the results will be biased.
Weights indicate how many population units are represented by the sample units. When producing estimates of sub-populations from the CURF, it is essential that they are calculated by adding the weights of persons in each category and not just by counting the sample number in each category. If each person's weight were to be ignored when analysing the data to draw inferences about the population, then no account would be taken of a person's chance of selection or of different response rates across population groups, with the result that the estimates produced could be biased. The application of weights ensures that estimates will conform to an independently estimated distribution of the population by age, by sex, etc. rather than to the distributions within the sample itself. For details on the SDAC weighting process, see Weighting, Benchmarking and Estimation in the Explanatory Notes of Disability, Ageing and Carers, Australia: Summary of Findings, 2015 (cat. no. 4430.0).
Weight Variables
There are two weight variables on the file:
Household Weight (FINWTH)
Person Weight (FINWTP)
Using Weights
What you count depends on the level from which you select the weight. A Household level weight estimates the number of households with a particular characteristic. Similarly, the weight included in the Family level estimates the number of families, and the weight included in the Income unit level estimates the number of income units, with the selected characteristic. Only persons living in households are included at the Household, Family and Income unit levels.
The person weight, stored on the Person level and below, provides an estimate of the number of persons with the selected characteristic. When the weights from levels five to ten are used, the population is restricted to persons who have a record on the particular level, but will be repeated for each instance of the characteristic. For example, the weight included on the Conditions level is attached to each condition record and therefore will be repeated for each person where they have more than one condition.
|  |
 | | |  |
 Level of Data Item Level of Data Item | Weight applied to level | Estimates if use Person Weight | |
|  |
 Household level Household level | Household weight (FINWTH) | Households with the specified characteristics. | |
 Family level Family level | Household weight (FINWTH) | Households containing one or more selected family units with the specified characteristics. | |
| Income unit level | Household weight (FINWTH) | Households containing one or more selected income units with the specified characteristics. | |
 Person level Person level | Person Weight (FINWTP) | Persons with the specified characteristics. | |
 All conditions level All conditions level | Person Weight (FINWTP) | Persons with one or more conditions with the specified characteristics. | |
 Restrictions level Restrictions level | Person Weight (FINWTP) | Persons with one or more restrictions with the specified characteristics. | |
 Specific activities level Specific activities level | Person Weight (FINWTP) | Persons with one or more specific activities with the specified characteristics. | |
 All recipients level All recipients level | Person Weight (FINWTP) | Recipients of care with one or more of the specified characteristics. | |
 Broad activities level Broad activities level | Person Weight (FINWTP) | Persons with one or more broad activities with the specified characteristics. | |
 Assistance providers level Assistance providers level | Person Weight (FINWTP) | Persons with one or more assistance providers with the specified characteristics. | |
|  |
Caution should be used if the ‘Household’ weight is applied to items from the Person level or below. For example, if the household weight is applied to a Person level demographic data item, such as ‘Sex’, the table produced will show the number of households with one or more selected persons of that sex. Since households can contain up to six people in the SDAC, this will result in some households being counted twice, once for females and once for males. |
Replicate weights have also been included and these can be used to calculate the standard error. For more information, refer to the Reliability of Estimates section below.
IDENTIFIERS
Every record on each level of the file is uniquely identified.
The identifiers ABSHID, ABSFID, ABSIID, ABSPID, ABSCID, ABSRSID, ABSSAID, ABSRCID, ABSBAID and ABSAPID appear on all levels of the file. Where the information for the identifier is not relevant for a level, it has a value of 0. See the Data Item List in the Downloads tab for details on which ID equates to which level.
Each household has a unique thirteen digit random identifier, ABSHID. This identifier appears on the Household level and is repeated on each level on each record pertaining to that household. The combination of identifiers uniquely identifies a record at a particular level as shown below:
2. Family = ABSHID + ABSFID
3. Income unit = ABSHID + ABSFID + ABSIID
4. Person = ABSHID + ABSFID + ABSIID + ABSPID
5. All conditions = ABSHID + ABSFID + ABSIID + ABSPID + ABSCID
6. Restrictions = ABSHID + ABSFID + ABSIID + ABSPID + ABSRSID
7. Specific Activities = ABSHID + ABSFID + ABSIID + ABSPID + ABSSAID
8. All recipients: see Combining carer and recipient data section below for a detailed explanation.
9. Broad Activities = ABSHID + ABSFID + ABSIID + ABSPID +ABSBAID
10. Assistance providers = ABSHID + ABSFID + ABSIID + ABSPID + ABSBAID + ABSAPID
The Household record identifier, ABSHID, assists with linking people from the same household, and also with household characteristics such as geography (located on the household level), to the Person records. When merging data with a level above, only those identifiers relevant to the level above are required.
|
|
Collection component identifiers
The Person level contains the item POPESTAB (Persons living in establishments) to indicate whether the data were collected in the household or cared accommodation component. The item POPESTAB has the category 'Living in an establishment' for the cared accommodation component and 'Not living in an establishment' for the household component. This item can be copied from the Person level to other levels of the file as required.
Copying information across levels
Identifiers can be used to copy information from one level of the file to another.
The following SAS code is an example of copying information from a lower level to a level above:
PROC SORT DATA=DAC15RES /* Creates a sorted dataset based on the Restrictions level */ ;
BY ABSHID ABSFID ABSIID ABSPID ;
RUN ;
DATA SUMMARY (KEEP=ABSHID ABSFID ABSIID ABSPID MENTUND) ; /* Create a new data item to identify respondents who have a learning or understanding difficulty or mental illness*/
SET DAC15RES;
BY ABSHID ABSFID ABSIID ABSPID;
RETAIN MENTUND ;
IF FIRST.ABSPID THEN MENTUND=2 ; /*This step will go through each Restriction record within each unique combination of ABSHID, ABSFID, ABSIID and ABSPID and assign a value of 2 to the new data item*/
IF RESTRCT=7 OR RESTRCT=14 THEN MENTUND=1 ; /* This sets the new data item to 1 if a Restriction level record indicates a learning or understanding difficulty or mental illness */ ;
IF LAST.ABSPID THEN OUTPUT; /* This outputs the last record for each unique combination of ABSHID, ABSFID, ABSIID and ABSPID, including the final result of whether or not the respondent has a learning or understanding difficulty or mental illness */
RUN ;
PROC SORT DATA = DAC15PER; /* Creates a sorted dataset based on the Person level */ ;
BY ABSHID ABSFID ABSIID ABSPID ;
RUN ;
DATA MERGE_FILE ;
MERGE SUMMARY (IN=A) DAC15PER (IN=B) ;
BY ABSHID ABSFID ABSIID ABSPID ;
IF B AND NOT A THEN MENTUND=2 ; /* This sets all Person level records not on the Restriction level to 'Does not have learning or understanding difficulties or mental illness' */ ;
RUN ;
The following SAS code is an example of copying information from a higher level to a level below:
PROC SORT DATA=DAC15RES; /* Creates a sorted dataset based on the Restrictions level */;
BY ABSHID ABSFID ABSIID ABSPID;
RUN ;
PROC SORT DATA = DAC15PER; /* Creates a sorted dataset based on the Person level */ ;
BY ABSHID ABSFID ABSIID ABSPID;
RUN;
DATA MERGE_FILE ;
MERGE DAC15RES (IN=A) DAC15PER (KEEP=ABSHID ABSFID ABSIID ABSPID AGEPC SEX IN=B);
BY ABSHID ABSFID ABSIID ABSPID;
IF A AND B THEN OUTPUT; /* This step only keeps records which are present on both the Restriction and Person levels*/;
RUN;
This merge matches one Person record to many Restriction records. The data items copied from the person level ('AGEPC' and 'SEX' in the example) will be repeated for each record of the level they have been added to, Restrictions in this case. Each Restrictions record will therefore receive the same AGEPC and SEX of the Person to whom they belong.
Combining carer and recipient data
Combining carer and recipient data can sometimes be confusing because the recipient level dataset includes identifiers for both the
carer and the
recipient(s) of care. This allows for data about either the
carer or the
recipient(s) of care to be copied from other levels. Care needs to be taken to ensure the correct identifiers are used.
If you require data items about the
carer use the identifiers:
1. Carer = ABSHID + ABSFID + ABSIID + ABSPID
If you require data items about the
recipient of care use the identifiers:
2. Recipient of care= MAPHHDRX + MAPFAMRX + MAPINCRX + MAPPSNRX
The following SAS code (or equivalent) can be used to copy information about the
carer, such as their age and sex, from the Person level onto the Recipient level.
PROC SORT DATA=DAC15ALR; /* Creates a sorted dataset based on the Recipient level and sorted by carer identifiers */
BY ABSHID ABSFID ABSIID ABSPID;
RUN ;
PROC SORT DATA = DAC15PER; /* Creates a sorted dataset based on the Person level */
BY ABSHID ABSFID ABSIID ABSPID;
RUN;
DATA MERGE_FILE ;
MERGE DAC15ALR (IN=A) DAC15PER (KEEP=ABSHID ABSFID ABSIID ABSPID SEX AGEPC IN=B);
BY ABSHID ABSFID ABSIID ABSPID;
IF A AND B THEN OUTPUT; /*This step only keeps records for carers which are present on both the Recipient and Person level */
RUN;
The following SAS code (or equivalent) can be used to copy information about the
recipient of care, such as their age and sex, from the Person level onto the Recipient level.
DATA DAC15PER;
SET DAC15PER; /*Create a common identifier so that recipient of care records on the Recipient level can be linked to the Person level */
RECIPHID = put(ABSHID,13.);
RECIPFID = put(ABSFID,2.);
RECIPIID = put(ABSIID,2.);
RECIPPID = put(ABSPID,2.);
RUN;
DATA DAC15REC;
SET DAC15ALR; /*Create a common identifier so that recipient of care records on the Recipient level can be linked to the Person level */
RECIPHID = put(MAPHHDRX,13.);
RECIPFID = put(MAPFAMRX,2.);
RECIPIID = put(MAPINCRX,2.);
RECIPPID = put(MAPPSNRX,2.);
RUN;
PROC SORT DATA=DAC15PER;
BY RECIPHID RECIPFID RECIPIID RECIPPID; /* Creates a dataset sorted by recipient of care based on the Person level */
RUN;
PROC SORT DATA=DAC15REC;
BY RECIPHID RECIPFID RECIPIID RECIPPID; /* Creates a dataset sorted by recipient of care based on the Recipient level */
RUN;
DATA PERSON_RECIP;
MERGE DAC15REC (IN=A) DAC15PER (KEEP=RECIPHID RECIPFID RECIPIID RECIPPID SEX AGEPC IN=B);
BY RECIPHID RECIPFID RECIPIID RECIPPID;
IF A AND B; /* This step only keeps records for recipients of care which are present on both the Recipient and Person level */
RUN;
MULTI-RESPONSE ITEMS
A number of questions in the survey allowed respondents to provide one or more responses. Each response category for these multi-response data items is treated as a separate data item. On the CURF, these data items share the same identifier (SAS name) prefix but are each separately suffixed with a letter - A for the first response, B for the second response, C for the third response and so on.
For example, the multi-response data item 'Disability type(s)' has nineteen response categories. There are nineteen data items named RESTIMPA, RESTIMPB, RESTIMPC...RESTIMPS. Each data item in the series will have either a positive response code or a null response code. The 'Not Applicable' response in each data item represents the respondents not asked the questions (e.g. RESTIMPS with values of 0 or 19). The data item list identifies all multi-response items and lists the corresponding codes with the corresponding response categories.
Note that the sum of individual multi-response categories will be greater than the population applicable to the particular data item as respondents are able to select more than one response. |
RELIABILITY OF ESTIMATES
Standard Errors
Each record on the household level and person level contains 60 replicate weights in addition to the main weight and, by using these weights, it is possible to calculate standard errors for weighted estimates produced from the microdata. This method is known as the 60 group Jack-knife variance estimator.
Under the Jack-knife method of replicate weighting, weights were derived as follows:
- 60 replicate groups were formed with each group formed to mirror the overall sample (where units from a collection district all belong to the same replicate group and a unit can belong to only one replicate group)
- one replicate group was dropped from the file and then the remaining records were weighted in the same manner as for the full sample
- records in that group that were dropped received a weight of zero.
This process was repeated for each replicate group (i.e. a total of 60 times). Ultimately each record had 60 replicate weights attached to it with one of these being the zero weight.
Replicate weights enable variances of estimates to be calculated relatively simply. They also enable unit record
analyses such as chi-square and logistic regression to be conducted, which take into account the sample design. Replicate weights for any variable of interest can be calculated from the 60 replicate groups, giving 60 replicate estimates. The distribution of this set of replicate estimates, in conjunction with the full sample estimate (based on the general weight) is then used to approximate the variance of the full sample.
To obtain the standard error of a weighted estimate y, the same estimate is calculated using each of the 60 replicate weights. The variability between these replicate estimates (denoting y(g) for group number g) is used to measure the standard error of the original weighted estimate y using the formula:
where:
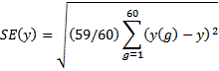
g = the replicate group number
y(g) = the weighted estimate, having applied the weights for replicate group g
y = the weighted estimate from the sample.
The 60 group Jack-knife method can be applied not just to estimates of the population total, but also where the estimate y is a function of estimates of the population total, such as a proportion, difference or ratio. For more information on the 60 group Jack-knife method of SE estimation, see
Research Paper: Weighting and Standard Error Estimation for ABS Household Surveys (Methodology Advisory Committee), July 1999 (cat. no. 1352.0.55.029).
Use of the 60 group Jack-knife method for complex estimates, such as regression parameters from a statistical model, is not straightforward and may not be appropriate. The method as described does not apply to investigations where survey weights are not used, such as in unweighted statistical modelling.
CURF DATA FILES
The 2015 Basic CURF can be accessed on CD-ROM, or via the RADL, and is available in SAS, SPSS and STATA formats. The CURF comprises the following files:
ASCII text format files
These files contains the raw confidentialised survey data in hierarchical comma delimited ASCII text format.
DAC15HH.csv contains the Household level data
DAC15FAM.csv contains the Family level data
DAC15IU.csv contains the Income Unit level data
DAC15PER.csv contains the Person level data
DAC15CON.csv contains the All Conditions level data
DAC15RES.csv contains the Restrictions level data
DAC15SPA.csv contains the Specific Activities level data
DAC15ALR.csv contains the All Recipients level data
DAC15BRA.csv contains the Broad Activities level data
DAC15PAS.csv contains the Assistance Providers level data
SAS files
These files contain the data for the CURF in SAS format.
DAC15HH.SAS7BDAT contains the Household level data
DAC15FAM.SAS7BDAT contains the Family level data
DAC15IU.SAS7BDAT contains the Income Unit level data
DAC15PER.SAS7BDAT contains the Person level data
DAC15CON.SAS7BDAT contains the All Conditions level data
DAC15RES.SAS7BDAT contains the Restrictions level data
DAC15SPA.SAS7BDAT contains the Specific Activities level data
DAC15ALR.SAS7BDAT contains the All Recipients level data
DAC15BRA.SAS7BDAT contains the Broad Activities level data
DAC15PAS.SAS7BDAT contains the Assistance Providers level data
SPSS files
These files contain the data for the CURF in SPSS format.
DAC15HH.SAV contains the Household level data
DAC15FAM.SAV contains the Family level data
DAC15IU.SAV contains the Income Unit level data
DAC15PER.SAV contains the Person level data
DAC15CON.SAV contains the All Conditions level data
DAC15RES.SAV contains the Restrictions level data
DAC15SPA.SAV contains the Specific Activities level data
DAC15ALR.SAV contains the All Recipients level data
DAC15BRA.SAV contains the Broad Activities level data
DAC15PAS.SAV contains the Assistance Providers level data
STATA files
These files contain the data for the CURF in STATA format.
DAC15HH.DTA contains the Household level data
DAC15FAM.DTA contains the Family level data
DAC15IU.DTA contains the Income Unit level data
DAC15PER.DTA contains the Person level data
DAC15CON.DTA contains the All Conditions level data
DAC15RES.DTA contains the Restrictions level data
DAC15SPA.DTA contains the Specific Activities level data
DAC15ALR.DTA contains the All Recipients level data
DAC15BRA.DTA contains the Broad Activities level data
DAC15PAS.DTA contains the Assistance Providers level data
INFORMATION FILES
Data item list
The Data item list contains all the data items, including details of categories and code values, that are available on the Basic CURF.
Formats file
| SAS_FMTS.sas7bcat is a SAS library containing formats |
Example code
DAC15B.SAS provides an example of how data can be loaded into SAS for Windows from DAC15B.CSV and can assist in creating code for your own analysis package.
Important information
IMPORTANT INFORMATION.pdf describes the file contents of the CURF and information on using the CURF
COPYRIGHT1.bat describes Copyright obligations for CURF users |
Frequency files
| The frequency file contains data item code values and category labels at each level, with frequencies for each value. |
 Quality Declaration
Quality Declaration  Print Page
Print Page
 Print All
Print All