TECHNICAL NOTE 6 SAMPLING ERRORS
SAMPLING ERRORS ASSOCIATED WITH STATISTICS PRODUCED FROM THE PES
1 Statistics produced from the PES are subject to sampling error. Since only a sample of dwellings was included in the PES, estimates derived from the survey may differ from figures which would have been obtained if all dwellings had been included in the survey. One measure of the likely difference is given by the standard error (SE) which indicates the extent to which an estimate might have varied by chance because only a sample was included.
2 The particular sample selected for the PES was only one of a number of possible samples. Each possible sample would yield different estimates. The SE measures the variation of all the possible sample estimates around the figures which would have been obtained if all dwellings had been included.
3 Given an estimate and the SE on that estimate, there are about two chances in three that the sample estimate will differ by less than one SE from the figure that would have been obtained if all dwellings had been included in the survey, and about nineteen chances in twenty that the difference will be less than two SEs.
4 The following example illustrates the use of the concept of SE. If an estimate of 2.5% has a SE of 0.1 percentage points there are two chances in three that the figure that would have been obtained if all dwellings had been included in the sample is in the range 2.5% ± (1 x 0.1%) or 2.4% to 2.6%, and nineteen chances in twenty that the figure is in the range 2.5% ± (2 x 0.1%), that is, between 2.3% and 2.7%.
5 For ease of use, the SEs corresponding to the net undercount rates are given next to the estimates in the tables throughout this publication.
SAMPLING ERRORS ON ESTIMATES OF DIFFERENCES
6 The sampling error on the difference between two estimates can be derived from their SEs. For the difference between two estimates x and y produced from the PES, the SE of the difference may be approximated by the following formula:
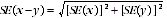
7 This approximation will be exact for differences between estimates in different states, for greater capital city versus rest of state regions, or for differences between estimates from different Censuses. However, for estimates within the same region there will be a negative correlation between the rates so that the approximation will generally underestimate the true SE.
8 For example, if the estimates of the rate of net undercount for usual residents in QLD greater capital city and rest of state are 2.7% and 1.4%, with SEs of 0.35 and 0.5 percentage points respectively, using the formula above the SE on the difference (1.3 percentage points) is:
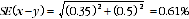
9 Therefore there are nineteen chances in twenty that the difference between the rates of undercount for usual residents between these two regions is within the range 1.3 ± (2 x 0.61) or 0.08 to 2.52 percentage points.
NON SAMPLING ERROR
10 The estimates of undercount are also subject to non-sampling errors which occur in all collections, whether censuses or surveys. Examples of this kind of error include imperfections in reporting by respondents and errors made in collection and processing of data. Every effort is made in both the Census and PES to minimise non-sampling error by careful design of forms, training and supervision of collectors and interviewers, and by using effective operating procedures. Types of non-sampling error arising from the way the PES is conducted and the way estimates are derived from the survey are discussed below.
11 A potential weakness in the PES method is its dependence on linking and matching as a means of deciding whether or not a given person or dwelling in the PES has been counted in the Census. The difficulties associated with the linking and matching process mean that there is a risk of failing to match people who were actually included in the Census. The effect of not matching when there should have been a match would be to overstate net undercount in the Census. However, the introduction of ADL in the 2011 PES processing phase has helped to reduce the likelihood of this type of error occurring.
12 While the Census and PES are conducted independently of each other, they are very similar in many respects. Thus, some weaknesses in the Census may also be shared by the PES leading to an understatement of net undercount. For example, dwellings missed by a Census collector are often difficult to find and so could be missed by a PES interviewer as well. In addition, people who avoid being included in the Census may also avoid being included in the PES. The use of benchmarks in estimation helps to control for the effect of this 'correlation bias'.
 Print Page
Print Page
 Print All
Print All